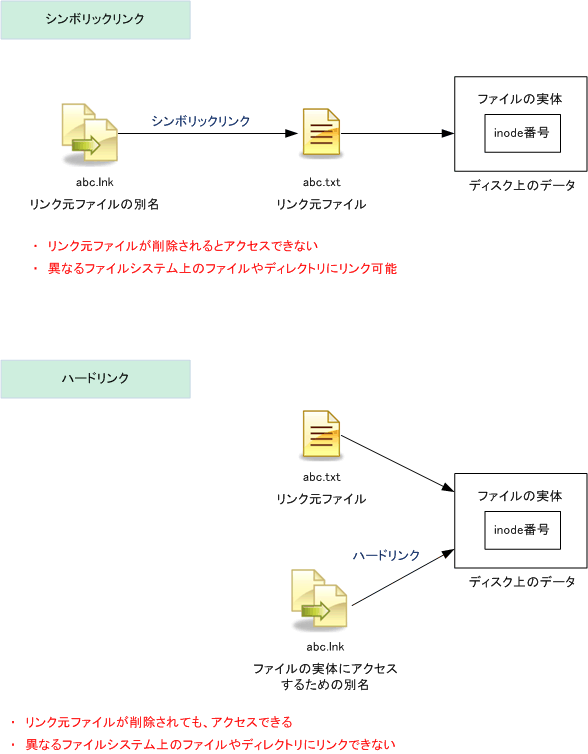
まずは双方向リストについて解説する。
Linuxkernel内部ではlist_headというデータ構造が用意されており、これが様々な場面で使用される。
このデータ構造はnextとprevの二つのメンバを持ち、データ構造に前後の概念を導入したいときに使用される。

list_headの定義
list_headは以下のように定義されている。
struct list_head { struct list_head *next, *prev; };
list_headの作成
list_headの作成にはLIST_HEADマクロを使用する。
#define LIST_HEAD_INIT(name) { &(name), &(name) } #define LIST_HEAD(name) \ struct list_head name = LIST_HEAD_INIT(name)
このマクロを使用する際にはLIST_HEAD(list_name)と宣言することで新しいlist_headを作成することができる
list_headの操作
list_headを操作するためにいくつかの関数が用意されている。
list_add(n, p): pが指す要素の直後に、nが指す要素を挿入するlist_add_tail(n, p): pが指す要素の直前に、nが指す要素を挿入するlist_del(p): pが指す要素を削除するlist_for_each(p): リストの先頭(h)で指定したリストの各要素を操作する。
プロセスリスト
存在するすべてのプロセスディスクリプタをリンクするためにも、list_headは使われています。
struct task_struct { ... struct list_head tasks; ... }
それぞれのtask_struct構造体は上記の通り、list_headがたのtasksメンバを持ち、このtasksメンバのprevメンバがひとつ前のtask_struct要素を指し、nextメンバがひとつ後のtask_struct要素を指しています。
プロセスリストの先頭には常にtask_structがたのinit_taskが格納されており、init_taskはいわゆるプロセス0、つまりswapperのプロセスディスクリプタとなります。
プロセスの親子関係
- プログラムから生成されたプロセスには親子関係があります。
- プロセスが複数のプロセスを生成するとき、プロセス間には兄弟関係が構築されます。
こうした兄弟/親子関係を表すメンバが、プロセスディスクリプタには存在します。
プロセスを生成したプロセスディスクリプタ
プロセスPを生成したプロセスディスクリプタはreal_parentメンバに格納されます。
(本物の)と名前が付く通り、このプロセスは削除される可能性もあります。
その場合はプロセス1を示すようになります。
struct task_struct { ... /* Real parent process: */ struct task_struct __rcu *real_parent; ... }
プロセスの現在の親
プロセスPの"現在の"親プロセスを示します。この値は通常はreal_pparentと同じですが、ほかのプロセスがptrace()システムコールを使用してプロセスを監視するときなど、異なる番号を示すケースもあります。
struct task_struct { ... /* Recipient of SIGCHLD, wait4() reports: */ struct task_struct __rcu *parent; ... }
プロセスのすべての子/親戚
プロセスの現在の子供、親戚のデータはchildren,siblingにそれぞれ格納されます。
struct task_struct { ... /* * Children/sibling form the list of natural children: */ struct list_head children; struct list_head sibling; ... }
pidhashテーブル
ハッシュ法について
ハッシュ法とは「目次の作成,分類分け」であり、配列内の要素へのアクセスを高速化するアルゴリズムです。
例えば、kill()システムコールを処理するときなどに、PIDから対応するプロセスディスクリプタを必要とする場合があります。この処理の高速化のために、ハッシュ法が使われています。
ハッシュ法では以下の二つの要素が出現します。
例えば、10で割ったときのあまりをハッシュ値とするというハッシュ関数があるとき、
どんなに膨大な集合でも、必ず10種類のどれかに分類分けできます。
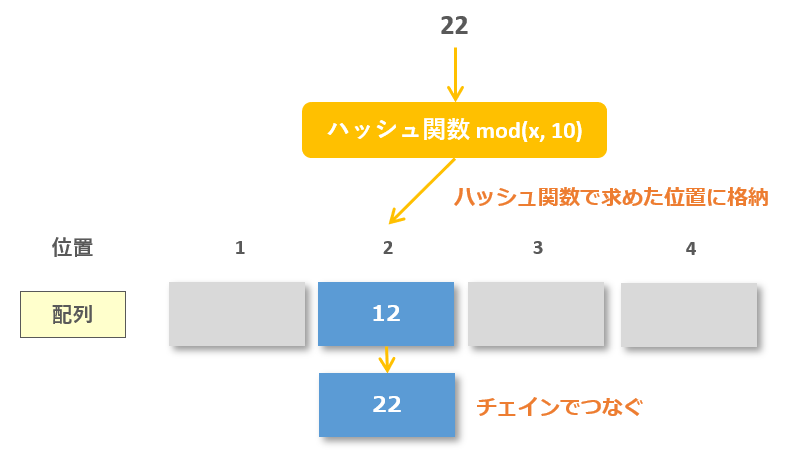
この図の場合、22のハッシュ値は2であるため、位置2の場所に22が格納されます。
これをすべての集合に対して処理を行い、ハッシュテーブルという目次を作成するのが目的です
from https://www.youtube.com/watch?v=bLw4HocrZiA
PIDハッシュテーブル一覧
実際、Linuxkernelではプロセスディスクリプタの特定のために、4つのハッシュテーブルが導入されました(PID_TYPE_MAXは最近導入?)
これら4つのテーブルを活用することにより、PID,TGID(スレッドグループID),PGID(プロセスグループID),SIDの探索を高速化します。
enum pid_type { PIDTYPE_PID, PIDTYPE_TGID, PIDTYPE_PGID, PIDTYPE_SID, PIDTYPE_MAX, }; /* * What is struct pid? * * A struct pid is the kernel's internal notion of a process identifier. * It refers to individual tasks, process groups, and sessions. While * there are processes attached to it the struct pid lives in a hash * table, so it and then the processes that it refers to can be found * quickly from the numeric pid value. The attached processes may be * quickly accessed by following pointers from struct pid. * * Storing pid_t values in the kernel and referring to them later has a * problem. The process originally with that pid may have exited and the * pid allocator wrapped, and another process could have come along * and been assigned that pid. * * Referring to user space processes by holding a reference to struct * task_struct has a problem. When the user space process exits * the now useless task_struct is still kept. A task_struct plus a * stack consumes around 10K of low kernel memory. More precisely * this is THREAD_SIZE + sizeof(struct task_struct). By comparison * a struct pid is about 64 bytes. * * Holding a reference to struct pid solves both of these problems. * It is small so holding a reference does not consume a lot of * resources, and since a new struct pid is allocated when the numeric pid * value is reused (when pids wrap around) we don't mistakenly refer to new * processes. */
コメント和訳
※構造体pidとは何ですか? * struct pid は、プロセス識別子のカーネルの内部概念です。 ※個々のタスク、プロセスグループ、セッションを指します。その間 * プロセスが接続されており、構造体 pid はハッシュ内に存在します * テーブルなので、それとそれが参照するプロセスを見つけることができます * 数値の pid 値から迅速に取得します。付属のプロセスは次のとおりです。 * struct pid からのポインターをたどることですぐにアクセスできます。 * * pid_t 値をカーネルに保存し、後で参照するには、 * 問題。もともとその pid を持っていたプロセスが終了した可能性があり、 * pid アロケータがラップされており、別のプロセスが来る可能性があります * そしてそのpidが割り当てられました。 * * 構造体への参照を保持することでユーザー空間のプロセスを参照 * task_struct に問題があります。ユーザー空間プロセスの終了時 * 役に立たなくなった task_struct はまだ保持されています。 task_struct と * スタックは約 10K の低カーネル メモリを消費します。より正確に * これは THREAD_SIZE + sizeof(struct task_struct) です。比較すると ※ struct pidは約64バイトです。 * * struct pid への参照を保持すると、これらの問題の両方が解決されます。 ※小さいのでリファレンスを保持してもあまり消費しません * リソース、および数値 pid が割り当てられたときに新しい構造体 pid が割り当てられるため * 値は再利用されます (pid がラップアラウンドするとき) 誤って新しいものを参照することはありません
PIDハッシュテーブル操作
検索
find_task_by_pid_type(type, nr)
pidがnrであるプロセスを、type型のハッシュテーブルから検索します。 - みつかった場合はディスクリプタへのポインタを返し - 見つからなかった場合はnullを返します
/* * Must be called under rcu_read_lock(). */ struct task_struct *find_task_by_pid_ns(pid_t nr, struct pid_namespace *ns) { RCU_LOCKDEP_WARN(!rcu_read_lock_held(), "find_task_by_pid_ns() needs rcu_read_lock() protection"); return pid_task(find_pid_ns(nr, ns), PIDTYPE_PID); }
追加
attach_pid(task, type, nr)
type型のpidハッシュテーブルのPID番号がnrの場所に、taskが指すプロセスディスクリプタを挿入します。
/* * attach_pid() must be called with the tasklist_lock write-held. */ void attach_pid(struct task_struct *task, enum pid_type type) { struct pid *pid = *task_pid_ptr(task, type); hlist_add_head_rcu(&task->pid_links[type], &pid->tasks[type]); }
pidを外すときはdetach_pid(task, type)を使用します。